- Linear Regression
-
Linear
Regression is supervised learning as you may remember from our last
lession, regression is supervised machine learning algorithm. Linear Regression
is a model that assumes a linear relationship between the input variables (x)
and the single output variable (y) and can predict the output. The
representation of linear regression is an equation that describes a line that
best fits the relationship between the input variables (x) and the output
variables (y), by finding specific weightings for the input variables called
coefficients (B). For example: y = B0 + B1 * x. Example: We will consider the
same regression example here(figure below), if we have a data set of house prices
with respect to house size, it can predict an unknown house price(q), if given
the house size(P).
-
Some good rules of thumb when using this
technique are to remove variables that are very similar (correlated) and to
remove noise from your data, if possible. It is a fast and simple technique and
good first algorithm to try.
- Logistic Regression
-
Logistic regression is like linear regression,
but instead of fitting a straight line or hyperplane, the prediction for the
output is transformed using a non-linear function called the logistic function
or sigmoid function. The function looks like a big S and transforms any output
to 0 to 1 range. For your reference please see the below figure(taken from wiki
https://en.wikipedia.org/wiki/Logistic_regression#/media/File:Exam_pass_logistic_curve.jpeg)
-
Like linear regression, logistic regression does
work better when you remove attributes that are unrelated to the output
variable as well as attributes that are very similar (correlated) to each other.
- Linear discriminate Analysis
-
It consists of statistical properties of your
data, calculated for each class. For a single input variable this includes: The
mean value for each class, The variance calculated across all classes.
Predictions are made by calculating a discriminate value for each class and
making a prediction for the class with the largest value
-
so it is a good idea to remove outliers from
your data beforehand. It’s a simple and powerful method for classification
predictive modelling problems.
- Classification and Regression Trees or Decision Trees
-
Decision trees are important type of algorithm
for predicting models. Each node represents a single input variable(x) and a
split point on that variable. The leaf node of the tree contains an output (y)
and the prediction for the model. Predictions are made by walking the splits of
the tree until arriving at a leaf node and output the class value at that leaf
node.
- Naïve Bais Algorithm
-
The definition of Bayes theorem is-
P(A|B)=P(B|A)P(A)/P(B), where A,B are events and P(A|B)- is a conditional
probability: the likelihood of event A occurring given that B is true. P(A) and
P(B) are the probabilities of observing A and B independently of each other;
this is known as the marginal probability.
-
Naive Bayes is called ‘naïve’ because it assumes
that each input variable is independent. This is a strong assumption and
unrealistic for real data, nevertheless, the technique is very effective on a
large range of complex problems.
-
The model is consist of to two types of
probabilities that can be calculated directly from the training data. They are
- A. probability of each class, B. Conditional probability of each class given
each x value. Once calculated, the probability model can be used to make
predictions for new data using Bayes Theorem.
- K-NN(K Nearest Neighbor) algorithm
-
K nearest neighbors algorithm is a simple
procedure to store all available cases and classifies new cases based on a
similarity measure. It is a simple, easy-to-implement supervised machine
learning algorithm which can be used for both classification and regression
algorithms. Predictions are made for a new data point after searching through
the entire training set for the K most similar neighbors and by summarizing the
output variable for those K instances. The idea of distance or closeness with
neighbors can be break down in very high dimensions (lots of input variables)
and that also can negatively affect the performance of the algorithm. This is
called the curse of dimensionality. Which
means you only use those input variables that are most relevant to predicting
the output variable.
-
As this algorithm is frequently used and easy to
implement, I will try to explain it with the following diagrams and data set.
Suppose, we have a data set with two groups, group A(blue) and group B(yellow)
as shown in the figure below and we want to classify the unknown point p1(red).
Do to so, the algorithm will try and find 4 nearest distanced neighbour(as k=4)
for the point p1 and label them accordingly.
- Learning Vector Quantization(LVQ)
-
A downside of K-Nearest Neighbors is that you
need to hang on to your entire training dataset. The Learning Vector
Quantization algorithm (or LVQ for short) is an artificial neural network
algorithm that allows you to choose how many training instances to hang onto
and learns exactly what those instances should look like.
-
The representation for LVQ is a collection of
codebook vectors. These are selected randomly in the beginning and adapted to
best summarize the training dataset over a number of iterations of the learning
algorithm. After learned, the codebook vectors can be used to make predictions
just like K-Nearest Neighbors. The most similar neighbor (best matching
codebook vector) is found by calculating the distance between each codebook
vector and the new data instance. The class value or (real value in the case of
regression) for the best matching unit is then returned as the prediction.
- Support Vector Machine(SVM)
- Support Vector Machine” (SVM) is a supervised
machine learning algorithm. This is another algorithm which can be used for
both classification and regression problems. However, it is mostly used in
classification problems. In this algorithm, we plot each data item as a point
in n-dimensional space (where n is number of features we have) with the value
of each feature being the value of a particular coordinate. Then, we perform
classification by finding the hyper-plane that differentiate the two classes
very.
In SVM, the hyperplane is selected input points that to best separates
the input variables into the points in the input variable space by their class,
either class 0 or class 1. In two-dimensions, you can visualize this as a line
and let’s assume that all of our input points can be completely separated by
this line. The SVM learning algorithm finds the coefficients that results in
the best separation of the classes by the hyperplane.
- The
best or optimal hyperplane that can separate the two classes is the line that
has the largest margin. Only these points are relevant in defining the
hyperplane and in the construction of the classifier. These points are called
the support vectors. They support or define the hyperplane. In practice, an
optimization algorithm is used to find the values for the coefficients that
maximizes the margin.
- Bagging and random forest
-
The bootstrap is a powerful statistical method
for estimating a quantity from a data sample. Such as a mean. You take lots of
samples of your data, calculate the mean and then average all of your mean
values to give you a better estimation of the true mean value.
-
In bagging, the same approach is used, but
instead for estimating entire statistical models, most commonly decision trees.
Multiple samples of your training data are taken then models are constructed
for each data sample. When you need to make a prediction for new data, each
model makes a prediction and the predictions are averaged to give a better
estimate of the true output value.
-
Random forest is a tweak on this approach where
decision trees are created so that rather than selecting optimal split points,
sub-optimal splits are made by introducing randomness.
- Adaboost classification
-
Boosting is an ensemble technique that attempts
to create a strong classifier from a number of weak classifiers. This is done
by building a model from the training data, then creating a second model that
attempts to correct the errors from the first model. Models are added until the
training set is predicted perfectly or a maximum number of models are added.
-
AdaBoost is used with short decision trees.
After the first tree is created, the performance of the tree on each training
instance is used to weight how much attention the next tree that is created
should pay attention to each training instance. Training data that is hard to
predict is given more weight, whereas easy to predict instances are given less
weight. Models are created sequentially one after the other, each updating the
weights on the training instances that affect the learning performed by the
next tree in the sequence. After all the trees are built, predictions are made
for new data, and the performance of each tree is weighted by how accurate it
was on training data.
Congratulation guys, now you know the 10 most commonly used machine learning algorithms. Next post I am planning to write some commonly asked interview questions on machine learning algorithms. So stay tuned, will share the next link soon. And don't forget to comment below for any suggestion and feedback. Till then bye, see you soon.
Next Topic is here :Top 10 interview question in ML/AI


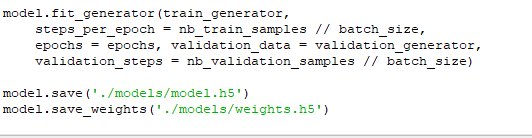
 You can clone the whole project from github here. Do let me know
if you have any feedback or suggestions. Hope you enjoyed coding with
me. Wish you all a very happy new year 2020 in advace.
You can clone the whole project from github here. Do let me know
if you have any feedback or suggestions. Hope you enjoyed coding with
me. Wish you all a very happy new year 2020 in advace.




























{kind=link}